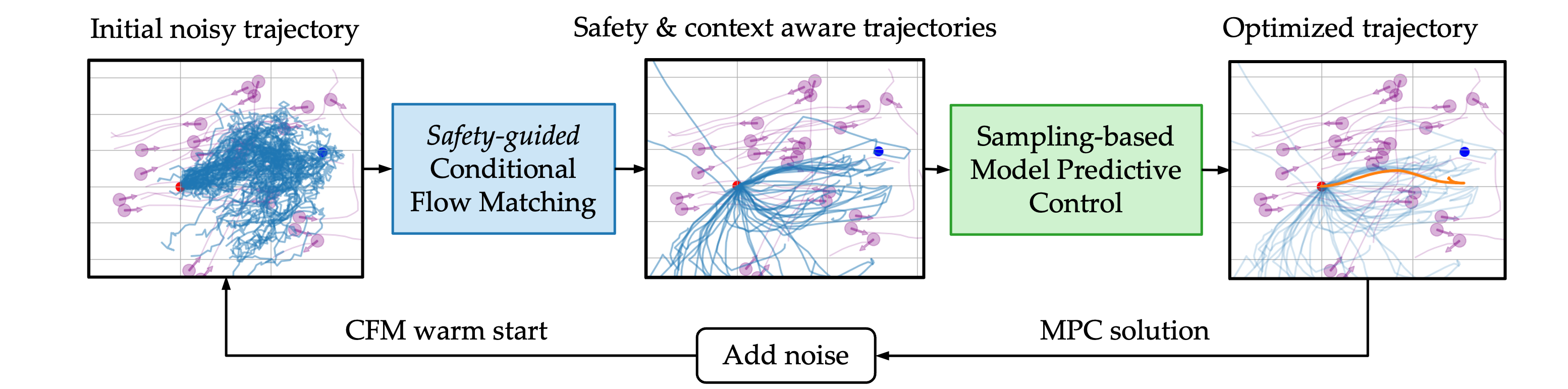
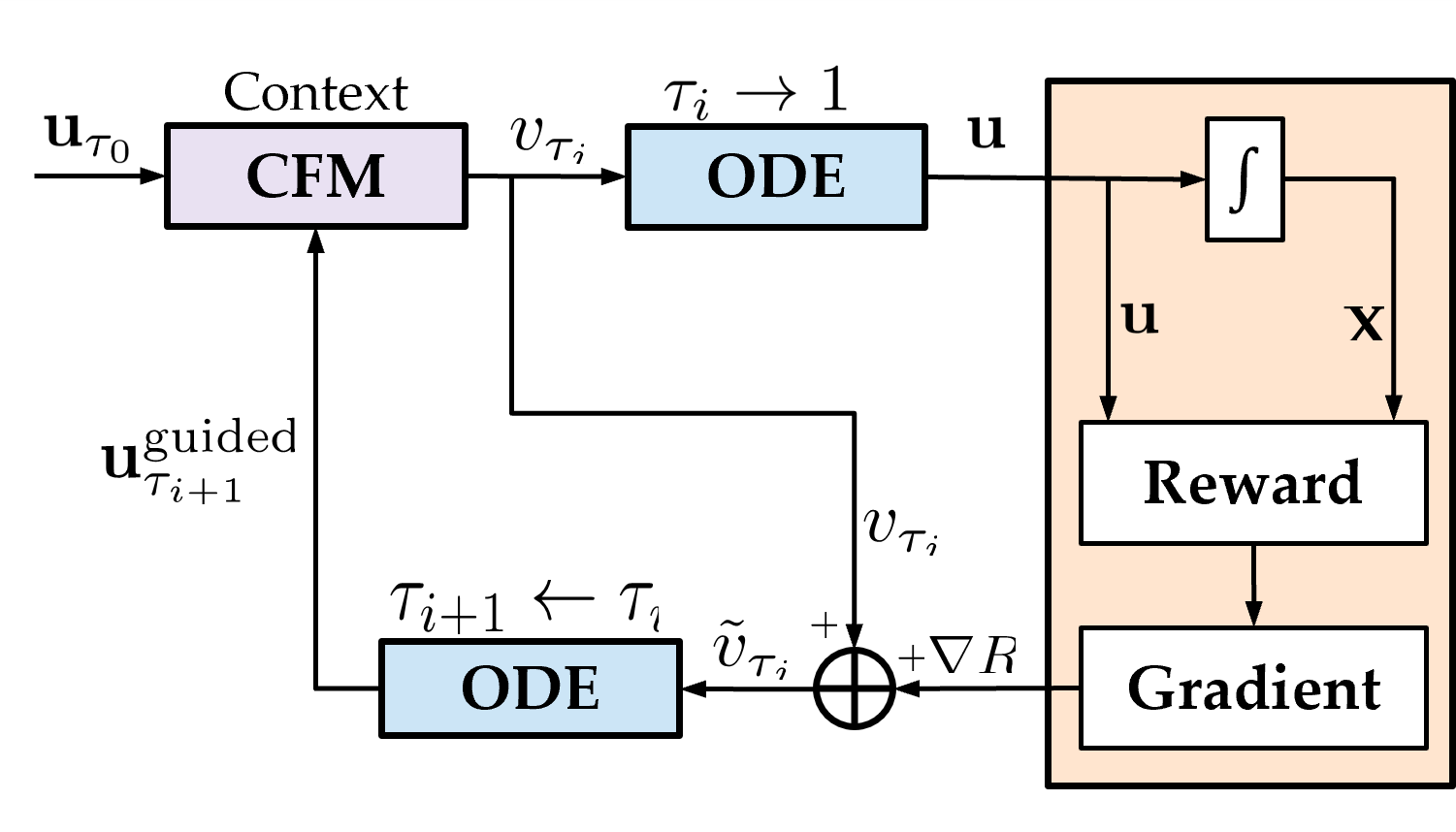
Planning safe and effective robot behavior in dynamic, human-centric environments remains a core challenge due to the need to handle uncertainty, adapt in real-time, and ensure safety. Optimization-based planners offer explicit constraint handling but rely on oversimplified initialization, reducing solution quality. Learning-based planners better capture multimodal possible solutions but struggle to enforce constraints such as safety. In this paper, we introduce a unified generation-refinement framework bridging learning and optimization with a novel \textit{reward-guided conditional flow matching} (CFM) model and model predictive path integral (MPPI) control. Our key innovation is in the incorporation of a \textit{bidirectional information exchange}: samples from a reward-guided CFM model provide informed priors for MPPI refinement, while the optimal trajectory from MPPI warm-starts the next CFM generation. Using autonomous social navigation as a motivating application, we demonstrate that our approach can flexibly adapt to dynamic environments to satisfy safety requirements in real-time.